Poster
Abstract
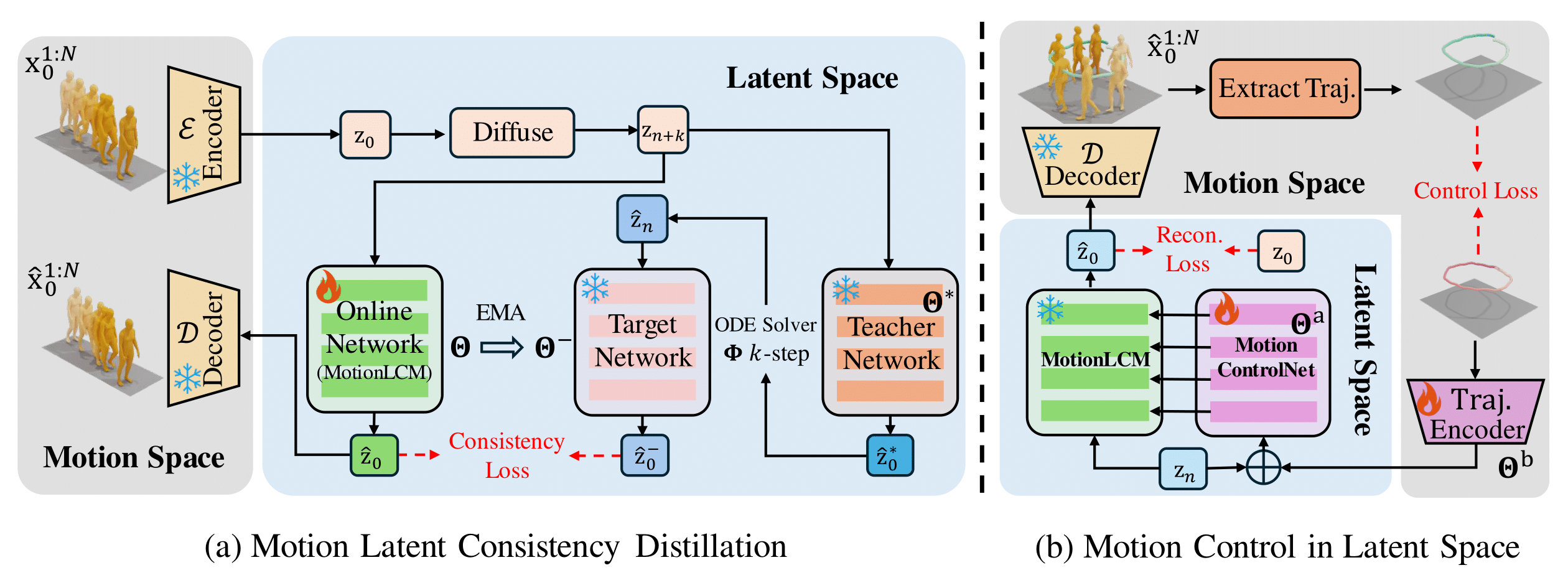
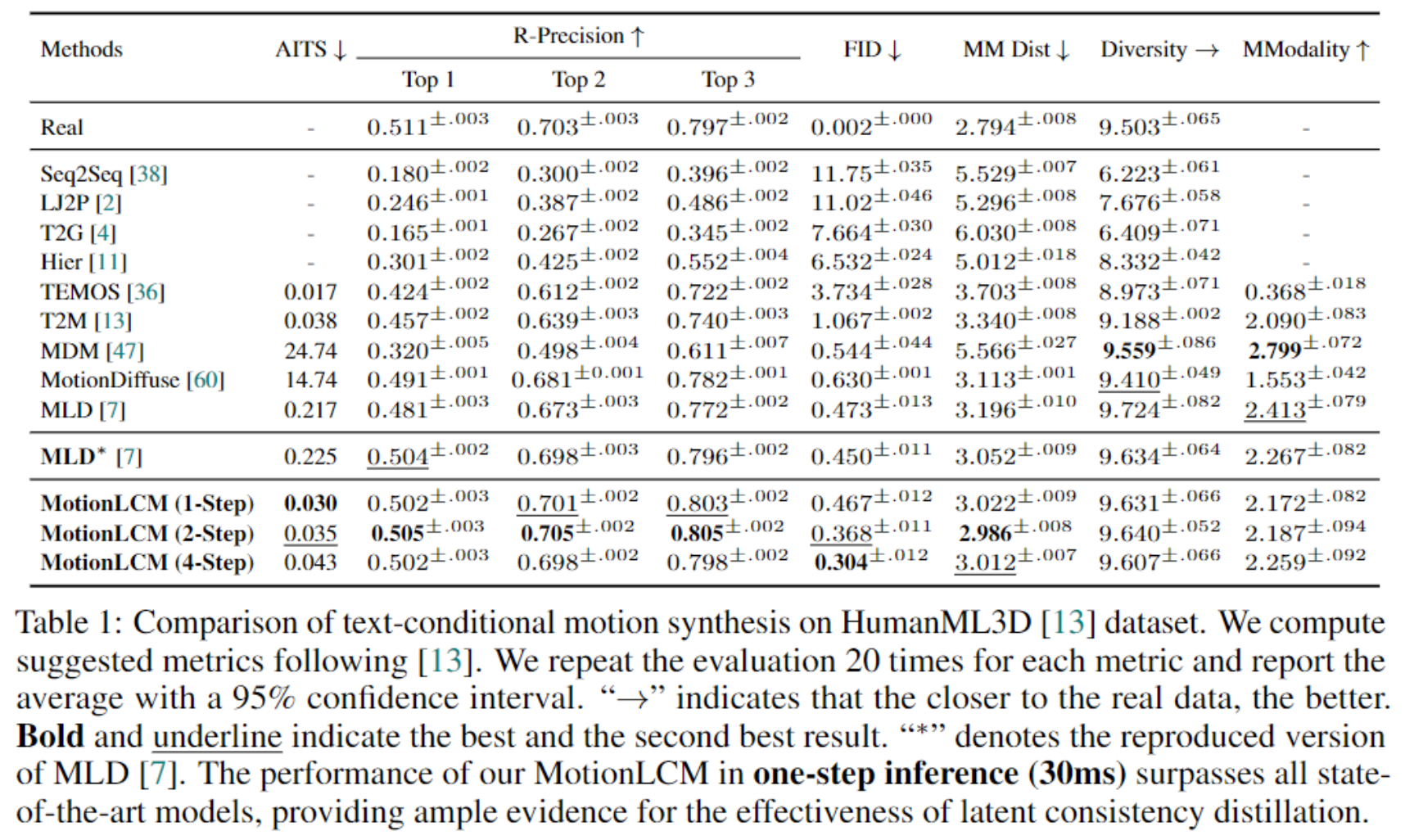
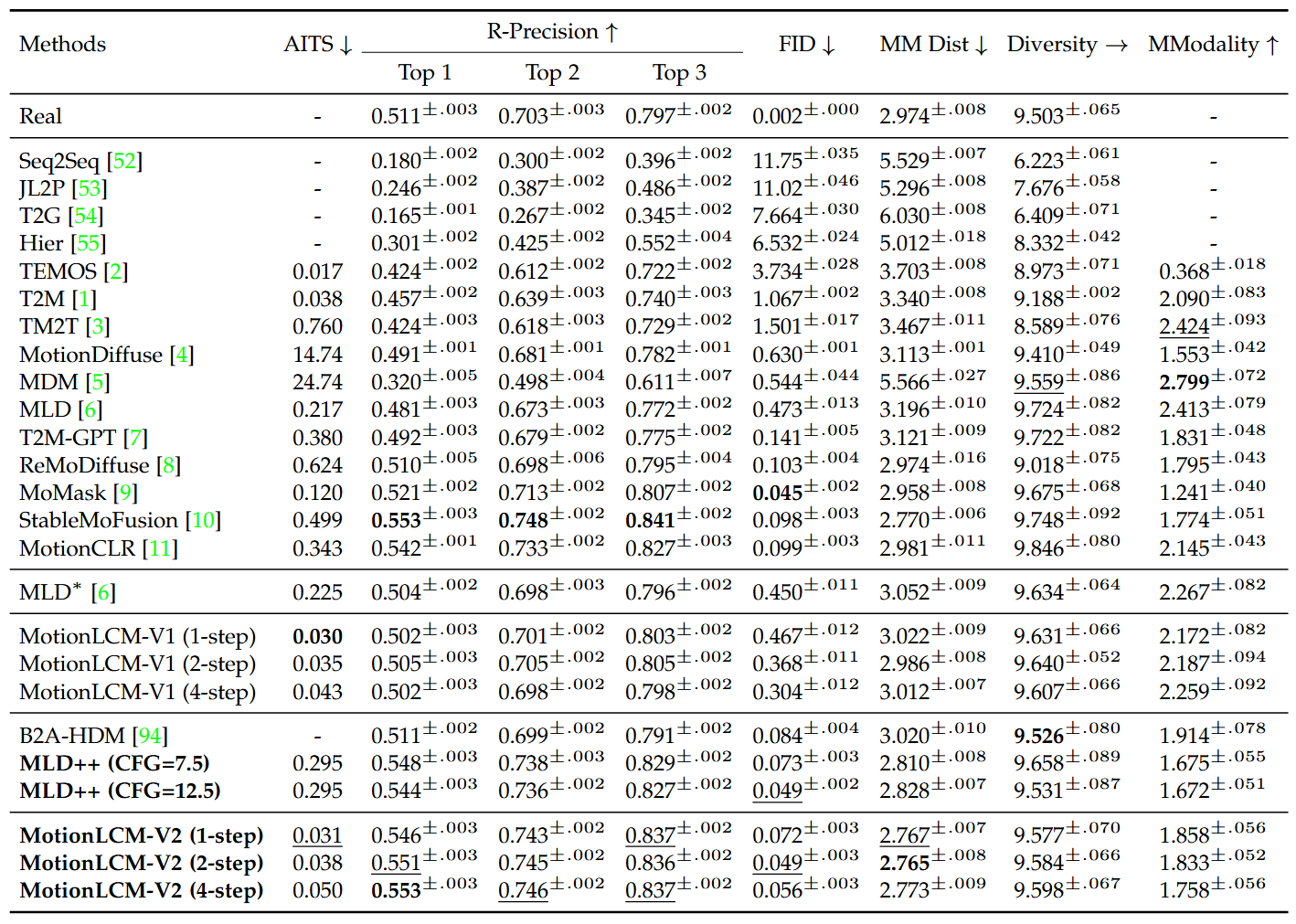
This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial-temporal control in text-conditioned motion generation suffer from significant runtime inefficiency. To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building on the motion latent diffusion model. By adopting one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation. To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (i.e., initial motions) in the vanilla motion space to further provide supervision for the training process. By employing these techniques, our approach can generate human motions with text and control signals in real-time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.